Get data ready for input-output analysis
June 08, 2026
Source:vignettes/getting_started.Rmd
getting_started.RmdIntroduction
Transitioning from more familiar, spreadsheet-based data management tools like Excel to R can present a steep learning curve for beginners. Recognizing this challenge, the {fio} package has been developed to bridge the gap, making it easier for students, analysts, and casual users to leverage the power of R for their input-output analysis.
The {fio} package simplifies the process of importing and managing input-output matrix data from Excel into R. This is particularly beneficial for those in the field of economics that relies on input-output analysis for understanding the flow of goods and services within an economy. By providing tools for both interactive and programmatic data import, {fio} ensures that users can choose the method that best fits their workflow and project needs. Along with easy of use, other base principles of {fio} design are clarity of computation (only doing what the user asks) and documentation (functions should clearly state their purpose without the user needing to read the source code).
This guide aims to introduce you to the core features of {fio},
guiding you through the process of importing data from Excel,
understanding the structure of the iom class, and utilizing
{fio}’s functionalities to perform comprehensive input-output analysis
with ease.
Importing data from Excel
One of the key aspects of {fio} is its ease of use. We were all beginners at some point, and data wrangling can be challenging. Although R is highly permissive with types and arguments—often outputting incorrect values or types instead of throwing an error—it still requires some effort for casual users to get data ready for use. Therefore, {fio} aims to reduce the initial hurdles for students or analysts who are transitioning from Excel-based input-output analysis to R.
This session focuses on using {fio} to import input-output matrix data from Excel, either interactively via an add-in or programmatically. By interactive import, I mean importing data from an open Excel spreadsheet, with the user selecting which rows and columns to import. This method is recommended for small, one-time, non-reproducible data imports. For larger imports, or when the data is to be used in a reproducible workflow, programmatic import is recommended.
Interactive import
To use the Import input-output data add-in, select the Import
input-output data option from the Addins menu if you are an
RStudio user. If you are using VSCode, open the command palette (F1 or
Ctrl+Shift+P), select R: Launch RStudio Addin, and then
choose Import input-output data. You can also call the
add-in directly by running fio:::fio_addin().
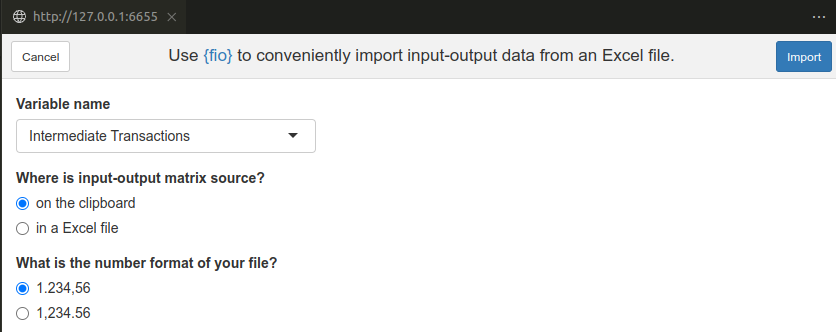
Import input-output data addin
Every chunk of data imported via the add-in is stored in the global
environment, under the name specified in the Variable name
field. If a name is not provided, select Custom and type
the desired name in the Custom variable name field.
When “on the clipboard” is selected (default), simply copy the data
in your Excel spreadsheet and click the Import button. The
data will be imported into R.
When “in an Excel file” is selected, you must provide the path to the
Excel file in the Source file field. Additionally, you need
to specify the sheet name and the range of cells to import. Optionally,
you can provide column or row name cell ranges.
Programmatic import
Under the hood, the add-in uses the import_element()
function, which is recommended for scripts and reproducible workflows.
The function has the following arguments:
variable_name = fio::import_element(
file = "path/to/file.xlsx",
sheet = "sheet_name", # sheet name
range = "B2:Z56", # cell range for data
col_names = "B2:Z2", # cell range for column names
row_names = "A2:A56" # cell range for row names
)This function allows you to specify the file path, sheet name, and cell ranges for the data, column names, and row names, providing a robust method for importing data programmatically.
The iom class
iom is an R6 class serving as the primary data structure
used by {fio} to store input-output data. It includes both required and
optional fields. The required fields are necessary for computing
technical coefficients, the Leontief inverse matrix, and output
multipliers. To compute additional features, you can add final demand
and value-added fields, some of which have dedicated slots for computing
specific multipliers. Additionally, there are slots for storing the
results of various functions, such as the technical coefficients matrix,
the Leontief inverse, key sectors, the Ghosh inverse, and more. You can
check all available slots and methods of the iom class in
the package
documentation.
In order to instantiate a new iom object, as every R6
class1,
you need to use the new() method. A new iom
object requires an id to help you identify the object
(especially when you have multiple iom objects in your
environment), a intermediate_transactions matrix, and a
total_production vector. The other slots are optional and
can be filled (or removed) later if needed with add() and
remove() methods.
Let’s create a new iom object with some random data:
# Create a new iom object
my_iom <- fio::iom$new(
id = "my_iom",
intermediate_transactions = matrix(as.numeric(sample(100:1000, 25)), nrow = 5),
total_production = matrix(as.numeric(sample(5000:10000, 5)), nrow = 1)
)
print(my_iom)
#> <iom>
#> Public:
#> add: function (matrix_name, matrix)
#> allocation_coefficients_matrix: NULL
#> clone: function (deep = FALSE)
#> close_model: function (sectors)
#> compute_allocation_coeff: function ()
#> compute_field_influence: function (epsilon)
#> compute_ghosh_inverse: function ()
#> compute_hypothetical_extraction: function (matrix = "ghosh")
#> compute_key_sectors: function (matrix = "leontief")
#> compute_leontief_inverse: function ()
#> compute_multiplier_employment: function ()
#> compute_multiplier_output: function ()
#> compute_multiplier_taxes: function ()
#> compute_multiplier_wages: function ()
#> compute_tech_coeff: function ()
#> exports: NULL
#> field_influence: NULL
#> final_demand_matrix: NULL
#> final_demand_others: NULL
#> ghosh_inverse_matrix: NULL
#> government_consumption: NULL
#> household_consumption: NULL
#> hypothetical_extraction: NULL
#> id: my_iom
#> imports: NULL
#> initialize: function (id, intermediate_transactions, total_production, household_consumption = NULL,
#> intermediate_transactions: 514 562 278 625 294 917 217 398 328 343 113 473 764 701 ...
#> key_sectors: NULL
#> leontief_inverse_matrix: NULL
#> multiplier_employment: NULL
#> multiplier_output: NULL
#> multiplier_taxes: NULL
#> multiplier_wages: NULL
#> occupation: NULL
#> operating_income: NULL
#> remove: function (matrix_name)
#> set_max_threads: function (max_threads)
#> taxes: NULL
#> technical_coefficients_matrix: NULL
#> total_production: 6789 9306 7979 6613 5554
#> update_final_demand_matrix: function ()
#> update_value_added_matrix: function ()
#> value_added_matrix: NULL
#> value_added_others: NULL
#> wages: NULL
#> Private:
#> iom_elements: function ()For now, intermediate_transactions and
total_production are the only not NULL slots.
We can compute the technical coefficients matrix by calling the
compute_tech_coeff() method:
# Compute technical coefficients matrix
my_iom$compute_tech_coeff()
print(my_iom)
#> <iom>
#> Public:
#> add: function (matrix_name, matrix)
#> allocation_coefficients_matrix: NULL
#> clone: function (deep = FALSE)
#> close_model: function (sectors)
#> compute_allocation_coeff: function ()
#> compute_field_influence: function (epsilon)
#> compute_ghosh_inverse: function ()
#> compute_hypothetical_extraction: function (matrix = "ghosh")
#> compute_key_sectors: function (matrix = "leontief")
#> compute_leontief_inverse: function ()
#> compute_multiplier_employment: function ()
#> compute_multiplier_output: function ()
#> compute_multiplier_taxes: function ()
#> compute_multiplier_wages: function ()
#> compute_tech_coeff: function ()
#> exports: NULL
#> field_influence: NULL
#> final_demand_matrix: NULL
#> final_demand_others: NULL
#> ghosh_inverse_matrix: NULL
#> government_consumption: NULL
#> household_consumption: NULL
#> hypothetical_extraction: NULL
#> id: my_iom
#> imports: NULL
#> initialize: function (id, intermediate_transactions, total_production, household_consumption = NULL,
#> intermediate_transactions: 514 562 278 625 294 917 217 398 328 343 113 473 764 701 ...
#> key_sectors: NULL
#> leontief_inverse_matrix: NULL
#> multiplier_employment: NULL
#> multiplier_output: NULL
#> multiplier_taxes: NULL
#> multiplier_wages: NULL
#> occupation: NULL
#> operating_income: NULL
#> remove: function (matrix_name)
#> set_max_threads: function (max_threads)
#> taxes: NULL
#> technical_coefficients_matrix: 0.0757107084990426 0.0827809692149065 0.0409485933127117 ...
#> total_production: 6789 9306 7979 6613 5554
#> update_final_demand_matrix: function ()
#> update_value_added_matrix: function ()
#> value_added_matrix: NULL
#> value_added_others: NULL
#> wages: NULL
#> Private:
#> iom_elements: function ()Now the technical_coefficients_matrix slot is filled.
You can access the slots using the $ operator:
# Access slots
print(my_iom$technical_coefficients_matrix)
#> 1 2 3 4 5
#> 1 0.07571071 0.09853858 0.01416218 0.13110540 0.08174289
#> 2 0.08278097 0.02331829 0.05928061 0.12218358 0.16906734
#> 3 0.04094859 0.04276811 0.09575135 0.02873129 0.02250630
#> 4 0.09206069 0.03524608 0.08785562 0.06759413 0.11127116
#> 5 0.04330535 0.03685794 0.08798095 0.11311054 0.09452647Other methods available are compute_leontief_inverse(),
compute_multiplier_output(),
compute_influence_field(),
compute_key_sectors(),
compute_allocation_coeff(),
compute_hypothetical_extraction(),
compute_ghosh_inverse(), and close_model().
Their names are clear and self explanatory. You can also chain these
methods to do all at once:
# Chain methods
my_iom$compute_tech_coeff()$compute_leontief_inverse()$compute_key_sectors()
print(my_iom$key_sectors)
#> sector power_dispersion sensitivity_dispersion power_dispersion_cv
#> 1 1 0.9624528 1.0431749 1.476627
#> 2 2 0.8657939 1.0855633 1.544105
#> 3 3 0.9813142 0.8523568 1.549744
#> 4 4 1.0882097 1.0191312 1.249759
#> 5 5 1.1022294 0.9997737 1.273982
#> sensitivity_dispersion_cv key_sectors
#> 1 1.356853 Strong Forward Linkage
#> 2 1.234939 Strong Forward Linkage
#> 3 1.774139 Non-Key Sector
#> 4 1.340143 Key Sector
#> 5 1.413387 Strong Backward Linkage